Despite the advancements in diffusion-based image style transfer, existing methods are commonly limited by 1) semantic gap: the style reference could miss proper content semantics, causing uncontrollable stylization; 2) reliance on extra constraints (e.g., semantic masks) restricting applicability; 3) rigid feature associations lacking adaptive global-local alignment, failing to balance fine-grained stylization and global content preservation.
These limitations, particularly the inability to flexibly leverage style inputs, fundamentally restrict style transfer in terms of personalization, accuracy, and adaptability.
To address these, we propose StyleGallery, a training-free and semantic-aware framework that supports arbitrary reference images as input and enables effective personalized customization.
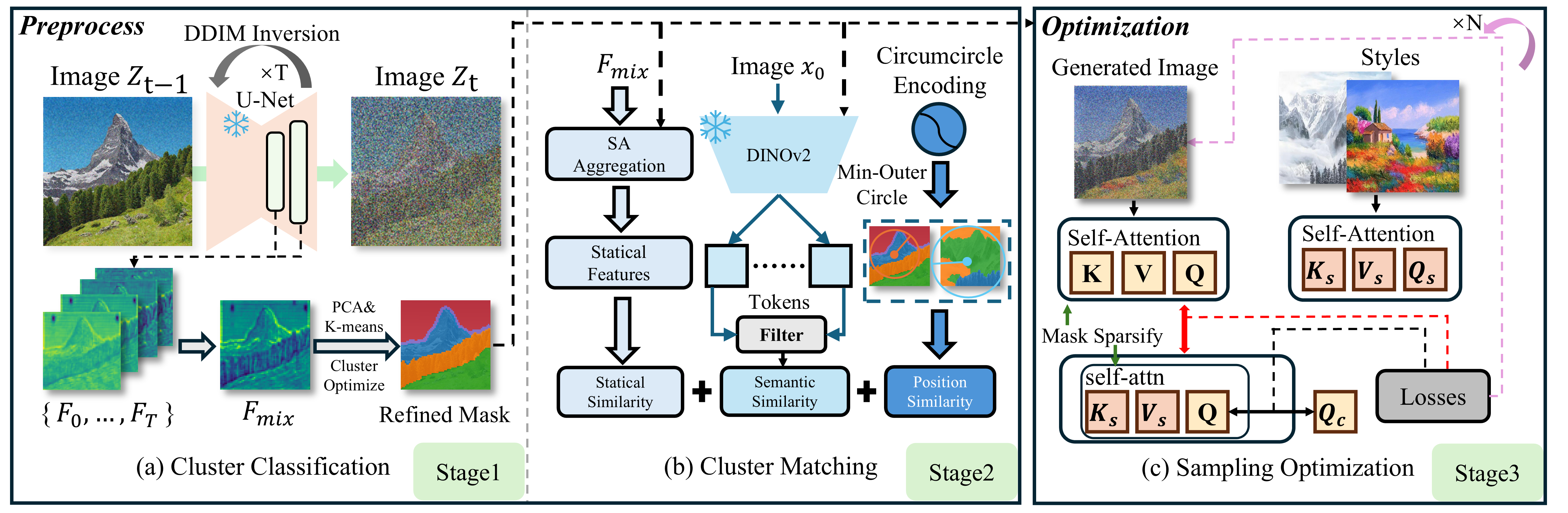
It comprises three core stages: semantic region segmentation (adaptive clustering on latent diffusion features to divide regions without extra inputs); clustered region matching (block filtering on extracted features for precise alignment); and style transfer optimization (energy function–guided diffusion sampling with regional style loss to optimize stylization).
Experiments on our introduced benchmark demonstrate that StyleGallery outperforms state-of-the-art methods in content structure preservation, regional stylization, interpretability, and personalized customization, particularly when leveraging multiple style references.